Personal Intelligence At Home
The world of open-source large language models (LLMs) has been rapidly taking off, especially with the arrival of Meta's LLama and first open-source tools for running them, such as Georgi Gerganov's llama.cpp. Nowadays, it feels like we see multiple releases per week on Hugging Face ranging from startups, such as Mistral and Anthropic, to established big players joining the field, such as Microsoft with the Phi-family of models and Google with their Gemma models.
This development has given ordinary people the possibility to run their own, private LLMs on consumer hardware. Forums like r/LocalLlama are great to see the experience of others with various models and open-source tools.
Inspired by this, I decided to convert my old Tower PC into an on-demand GPU server for running LLMs and image generation models at home.
The Problem
If you actually want to run your own, fairly capable LLMs at home and want reasonable speeds that are enough to ditch ChatGPT, you need a GPU at the moment.
But if you're like me and have the privilege to live in a country with one of the highest consumer electricity prices in the EU (and the world), you likely know that it can be quite expensive to keep your appliances running 24/7.
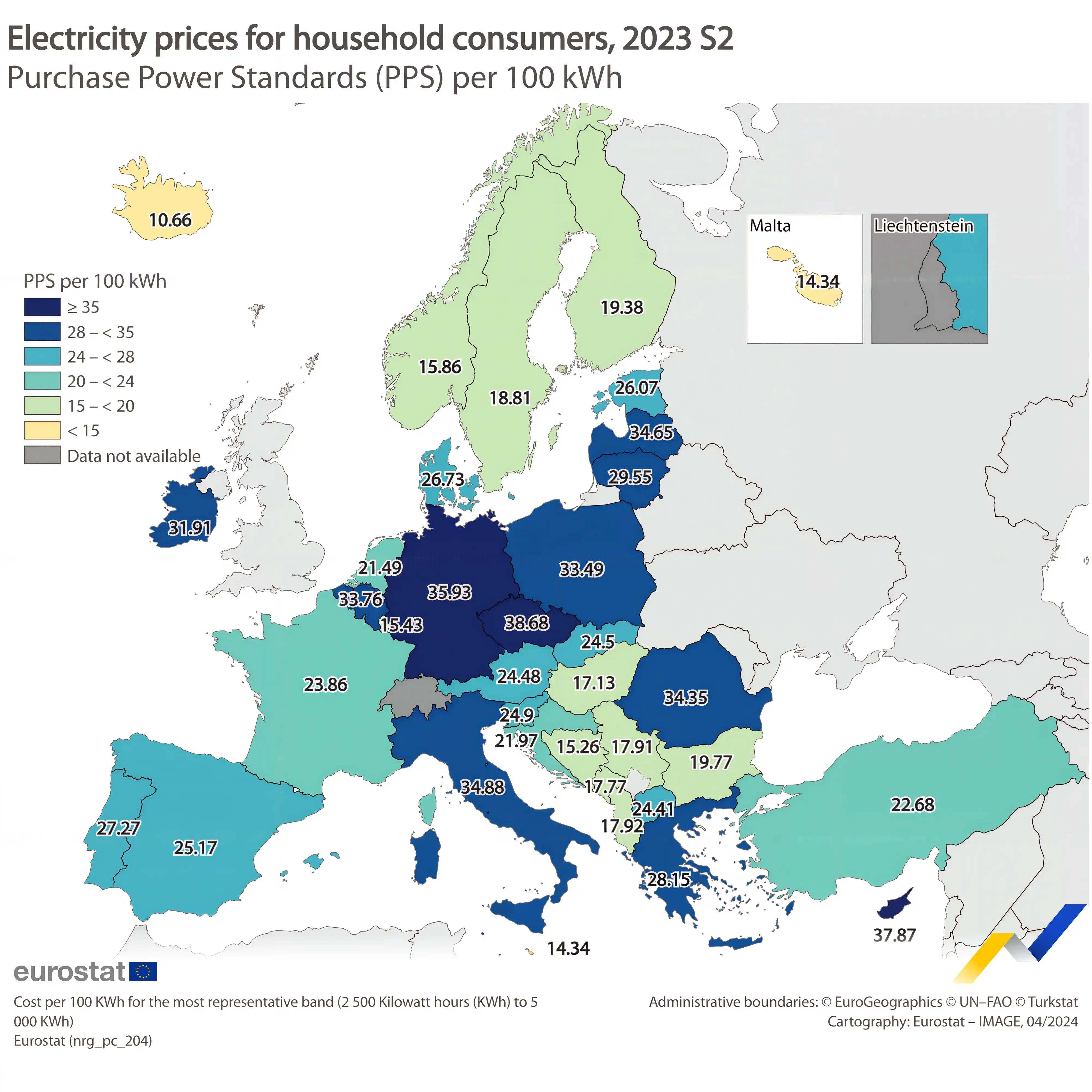
Running a capable LLM at home requires a significant amount of power, especially if you want to avoid the limitations of CPU-only setups. For instance, my GPU server, a tower PC with a 12700K CPU and an NVIDIA RTX 3090, consumes around 50 W when idle. With electricity prices at 35 cents per kWh, that's roughly 15€ per month. The meaning of expensive is very subjective, but if I can avoid paying the equivalent of <insert your favorite streaming/music provider>'s fees every month while also learning about various technical concepts, I think that's a fantastic deal!
Another big downside is that my GPU server makes an audible sound (even when idle) due to its fans and I don't have a good place to hide it at the moment.
While I could run LLMs on my 24/7 home server/Mini-PC's CPU, there is no way I can get the same token throughput for models in the 7-8B parameter range, as on the RTX 3090. Also, image generation on CPU is slooooow.

The Solution
TL;DR, Here is my new setup:
My Mini-PC (a Beelink Mini S12 Pro with an Intel N100 CPU) is running 24/7 and is used for various purposes besides LLMs/ImageGen, such as my home VPN (wireguard), IoT stuff (Home Assistant, Zigbee2MQTT, influxdb), and other self-hosted services (NextCloud, ...). It typically consumes around 25 Watts (including two external hard drives), which is a bullet I am willing to bite. The GPU Server, on the other hand, runs exclusively services that actually require GPU compute (currently ComfyUI for image generation, and Ollama for LLMs).
Waking up on demand
My first idea was to put the GPU Server into suspend (RAM), when it's not needed and wake it up on demand. In suspend, the server only draws <5 Watts.
But how can we wake it up via software? - Enter Wake-On-Lan (WOL), a mechanisms supported by most motherboards, where, if enabled, sending a magic Layer 2 packet to the server's NIC triggers a boot or wake-up event. Luckily, my GPU server supports it.
Now, the second question: How can we send the magic packet when we need Ollama/ComfyUI? At first, I was thinking of modifying certain client side software (such as simonw's llm, Open WebUI, or gptel for Emacs) to send the packet whenever I am interacting with it. Another idea would have been to manually sending the WOL packet before using the software, e.g., using a widget in Home Asisstant.
But in the end, I settled for a more reliable approach. Instead of letting the clients talk directly to my server, I let them talk to my Mini-PC instead, which then reverse proxies the connection to my server. In addition to forwarding the request, the proxy also sends a WOL packet to the GPU server, waking it up in the process. Fortunatly, someone already did the heavy lifing and wrote a WOL plugin for traefik. With the following config, I was able to achieve exactly what I wanted:
http:
middlewares:
traefik-wol:
plugin:
traefik-wol:
healthCheck: http://192.168.0.123:11434
macAddress: 01:23:45:67:89:ab
ipAddress: 192.168.0.123
routers:
ollama-router:
rule: "Host(`ollama.local`)"
entryPoints:
- web
service: ollama-service
middlewares:
- traefik-wol
comfyui-router:
rule: "Host(`comfyui.local`)"
entryPoints:
- web
service: comfyui-service
middlewares:
- traefik-wol
services:
ollama-service:
loadBalancer:
servers:
- url: "http://192.168.0.123:11434"
comfyui-service:
loadBalancer:
servers:
- url: "http://192.168.0.123:8188"
experimental:
devPlugin:
goPath: "/plugin"
moduleName: "github.com/MarkusJx/traefik-wol"
plugins:
traefik-wol:
moduleName: "github.com/MarkusJx/traefik-wol"
version: "v0.1.1"
Note that NVIDIA GPUs might behave weirdly after resuming from suspend, as might not restore all necessary memory. Enabling some SystemD services solved the issues for me. See here for some documentation about this.
Auto-Suspend
It's nice to have the server wake up on demand, but the actual goal was to have it be in suspend for as much as possible (to save money & reduce noise). Having it suspend automatically after each request is unrealistic, since LLMs are typically queried continuously (especially with a streaming API) and the user might ask further queries during a conversation. Instead, the server should be suspended, if, for a certain period of time, no new requests have been made.
To implement this, I wrote a simple bash script that runs every minute and checks if the following conditions are met:
- There is no process using the GPU besides ComfyUI (Ollama unloads models from the GPU after 5 minutes of inactivity).
- There is no active user session on the server.
- There is no active ssh session on the server.
- The system has been in this state for at least 5 minutes (note that this means that Ollama hasn't been queried for 10 minutes).
If they are all met, the system is suspended. Unfortunately ComfyUI hangs after waking up and needs to be restarted (potentially related to GPU memory, I might need to add an auto-unloading node to my workflows).
Here is the script (check_idle.sh):
#!/bin/bash
IDLE_TIMESTAMP_FILE=/tmp/idle_timestamp
current_time=$(date +%s)
time_seconds=$((10 * 60))
# Check for user sessions
active_sessions=$(loginctl list-sessions --no-legend | grep active | wc -l)
# Check for comfyui process
running_comfyui_processes=$(pgrep -c comfyui)
# Check for other GPU processes excluding comfyui, not sure how to do this more elegantly
num_non_comfyui_gpu_processes=$(nvidia-smi | awk '/Processes:/,/^\\s*$/' | grep -v 'Processes' | grep -v 'PID' | grep -v 'GPU' | grep -v Usage | grep -v '================' | grep -v -- '---------------------' | grep -v 'ComfyUI' | wc -l)
# Check for active SSHD sessions
active_sshd_sessions=$(ps aux | grep sshd-session | grep -v grep | wc -l)
if [[ $active_sessions -eq 0 ]] && [[ $num_non_comfyui_gpu_processes -eq 0 ]] && [[ $active_sshd_sessions -eq 0 ]]; then
echo "No user sessions, no other GPU processes, and comfyui can still be running"
if [[ -f ${IDLE_TIMESTAMP_FILE} ]]; then
idle_since=$(cat ${IDLE_TIMESTAMP_FILE})
idle_duration=$((current_time - idle_since))
echo "Idle duration: $idle_duration"
if [[ idle_duration -ge time_seconds ]]; then
echo "Going to suspend, since $time_seconds have passed"
systemctl suspend
rm ${IDLE_TIMESTAMP_FILE}
# Restart comfyui after suspend (this won't trigger until after resume)
systemctl restart comfyui.service
fi
else
echo ${current_time} > ${IDLE_TIMESTAMP_FILE}
fi
else
if [[ -f ${IDLE_TIMESTAMP_FILE} ]]; then
rm ${IDLE_TIMESTAMP_FILE}
fi
fi
And I am using a SystemD service + timer to run it once per minute:
# check_idler.service
[Unit]
Description=Check for idle condition and suspend
[Service]
ExecStart=/srv/check_idle.sh
# check_idler.timer
[Unit]
Description=Runs check_idle.sh every minute
[Timer]
OnBootSec=1min
OnUnitActiveSec=1min
[Install]
WantedBy=timers.target
Startup Times and Timeouts
At first I was worried about startup times and potential timeouts in client applications. So far, it seems like many clients have very high timeouts (multiple seconds) for their queries. This makes sense since some non-streaming LLM APIs might take a long time to compute the response.
With Open WebUI, for example, I had to wait about ten seconds until my PC was booted up and the chat interface was loaded. It seems they changed that in recent versions and now the chat interface loads instantly, but does not show Ollama Models until the said ten seconds have passed. Since this only happens once, subsequent requests will be responded to fast.
Conclusion
There we have it: An on-demand, less power-hungry GPU server running at home.
What I really like about the setup is, that we essentially hide the fact that we wake up the server on-demand transparently behind the APIs for Ollama (ollama.local) and ComfyUI (comfyui.local).
This allows me, for example, to simply run
OLLAMA_HOST=https://ollama.local/ ollama run llama3.1:latest
and the server gets woken up and lets me chat with Llama 3.
This works similarly with all kinds of clients. For example, Open WebUI will only talk to Ollama, when you load it in your browser, so we again, achieve a similar on-demand effect there.
I'm super happy with this setup and have been running it for the past couple of months and I hope this post brought some new inspirations to others, happy tinkering! 🙂